





Data Mining, Big Data, Data Scientist… Voici des termes à la mode dans le jargon d’entreprise, mais bien éloignés à première vue des considérations du naturaliste ! Et pourtant, derrière ce lexique se cache une nouvelle génération d’outils statistiques puissants, à même de solutionner aussi bien le traitement des données scientifiques que de structurer la collecte des futurs résultats terrains.
Bien-sûr, le domaine des Big Data a de quoi refroidir plus d’un naturaliste terrain. Parlez de Python à un ornithologue, et il pensera espèces exotiques rares plutôt que de langage informatique ! La faible affinité du naturaliste avec les outils informatiques est légendaire. Mais l’ornithologue dessinant sur son calepin papier une ébauche de carte barbouillée de coches est cependant devenu une caricature surannée. Désormais, il dialogue directement depuis le terrain avec des bases de données en ligne à l’aide de son smartphone.
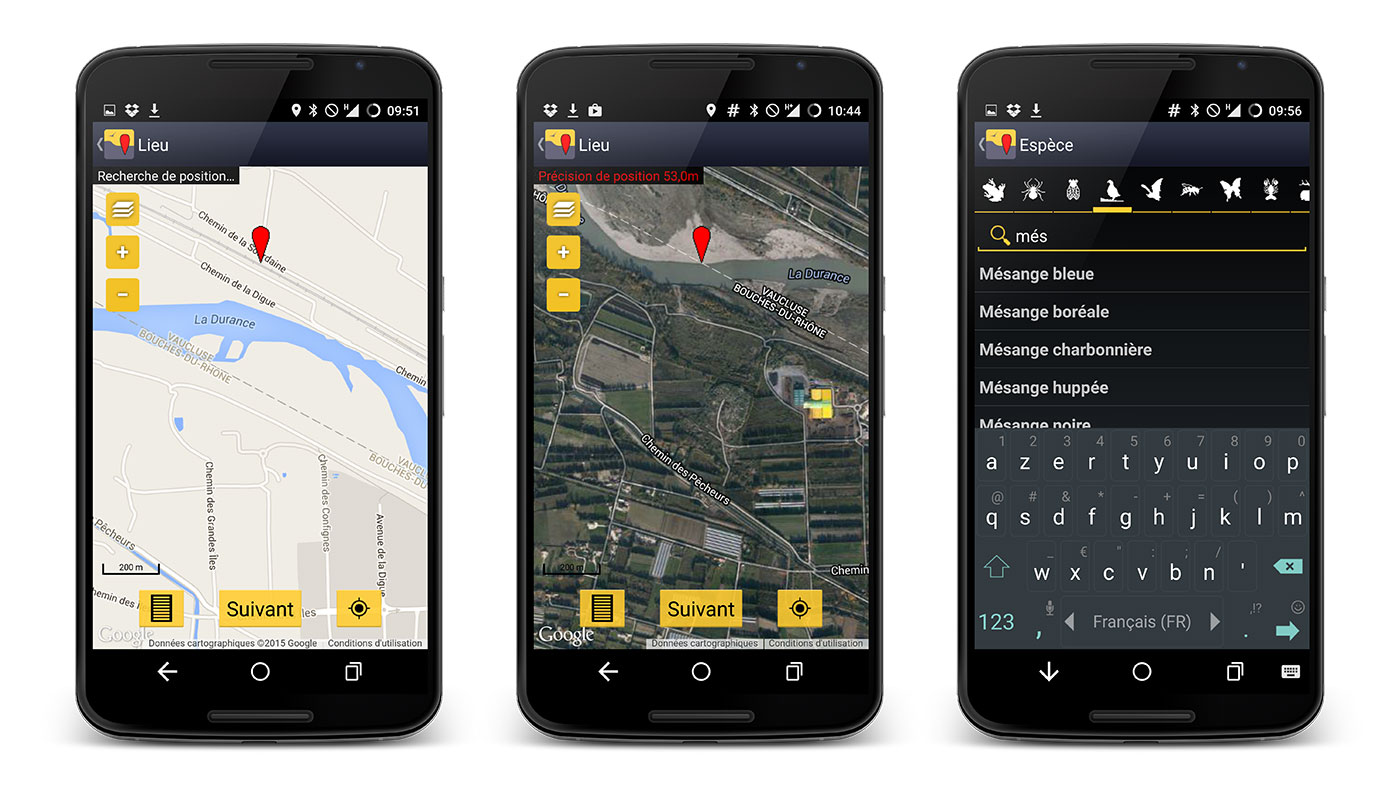
La Révolution du Naturaliste connecté
Depuis l’arrivée de l’Internet haut débit courant des années 2000, le quotidien du naturaliste a subi une véritable révolution numérique. Nous rentrons désormais nos données sur smartphones ou sites web, nous « googelons » pour trouver des interfaces de bases de données naturalistes, nous utilisons le webmapping pour savoir où observer la Mouette de Franklin repérée la veille par un cocheur fou… Que nous le voulions ou non, nous avons déjà mis un pied dans le naturalisme 2.0 !
Alors, le naturaliste va-t-il se transformer en « Data Naturalist » dans les années à venir, où avons-nous déjà pris le train du Data Mining sans le savoir ? Faut-il craindre ces nouveaux outils jugés illusoires et énergivores par certains écologistes ? Ou bien au contraire apprendre à les maîtriser de manière responsable ? Cet article revient sur les origines du Data Mining et ses principales définitions, avant d’aborder quelques exemples d’utilisation de ces outils statistiques en sciences naturelles.
Le Data Mining ou la Ruée vers l’Information

Le Data Mining est un anglicisme désignant les processus d’exploration informatique de bases de données et l’extraction d’informations nouvelles. Particulièrement à la mode dans le monde industriel, le Data Mining s’applique au monde de la finance, à la gestion de fichiers clientèle, au marketing, ou encore au secteur des assurances. Dans le domaine de la recherche médicale ou scientifique, le métier d’analyste de données ou Data Scientist prend aussi de l’importance.
En effet, avec la croissance exponentielle des bases de données conectées, la question de leur exploitation intelligente est devenue cruciale. Le Data Scientist ressemble à un prospecteur en pleine ruée vers l’or. Le Yukon est vaste, aussi où doit-il planter sa pioche pour découvrir une pépite ? Hors de question de procéder au hasard. Le Data Scientist utilise des analyses statistiques pour dénicher le bon filon d’informations.
L’exploration de données en statistiques n’est pas récente. Sa version moderne débute dans les années 60, lorsque le mathématicien Myron Tribus utilise le langage BASIC pour trier des données à partir de modèles statistiques. Le terme Dat Mining existe même alors dans le jargon des statisticiens, bien qu’il qualifie de manière péjorative la recherche de corrélations sans hypothèse précise dans un jeu de données. Il faudra attendre les années 80 pour que l’expression soit redécouverte par l’informaticien Rakesh Agrawal. Ce pionnier du Data Mining entamait alors des travaux d’exploration de données sur des bases de données de… 1 Mo ! Une taille qui laissera chacun juge des progrès informatiques réalisés en quarante ans.
L’apparition du Data Mining en Biologie
Au début du 21ème siècle, une avancée génétique majeure va contribuer à populariser le Data Mining auprès des biologistes. La Genome Database, qui présente l’ensemble des informations issues du séquençage du génome humain, marque alors les esprits par sa bibliothèque colossale de données. Face à l’accumulation d’informations de séquences, annotations, comparaisons et cartographies génétiques, il devient indispensable de recourir à des outils biostatistiques et bioinformatiques à grande échelle. Les Big Data volent donc au secours de la génomique.
Dans le domaine de l’écologie et de l’environnement, le terme de Data Mining n’apparaît que très récemment. Probablement en raison d’une diffusion progressive de ces outils vers toutes les branches de la biologie. Et pourtant, l’écologie est par définition une science au carrefour de nombreuses disciplines. Qu’elle se nourrisse de géosciences, de physique, de chimie et de biologie ne surprendra personne. Que les biostatistiques y jouent un rôle majeur non plus.
L’analyse statistique de données multivariées n’est d’ailleurs pas nouvelle dans la discipline. Le lecteur ayant suivi un cursus en biologie aura certainement en mémoire les Analyses en Composantes Principales (ACP). Aussi le recours aux Data Sciences n’est pas totalement étranger à la discipline, et représente même une continuité logique pour l’écologie scientifique en ce début des années 2020.
Les notions de base du Data Mining
Procédé d’analyse de données, le Data Mining repose sur des algorithmes complexes dont le Data Scientist en est rarement l’auteur. En tant qu’opérateur, il se limite à utiliser ces outils dans le but d’explorer des jeux de données riches et complexes selon différentes perspectives. La démarche vise à établir de nouvelles corrélations entre données et à repérer des motifs similaires (ou patterns). Ces informations nouvelles sont ensuite utilisées par l’entreprise pour améliorer ses résultats ou optimiser son fonctionnement, ou par le chercheur pour leur apporter une discussion scientifique.
En celà, le Data Mining est proche de l’informatique décisionnelle (ou Business Intelligence). Elle désigne les moyens, outils et méthodes de collecte de donnée d’une entreprise ainsi que les stratégies de restitution et de modélisation des informations collectées dans un but décisionnel. Le Data Mining introduit pour sa part une dimension exploratoire. C’est à dire la recherche d’informations inédites que l’utilisateur devra juger pertinentes ou non.
Trois notions sont donc essentielles au Data Mining : les données, les informations et le savoir.
- Les données sont des variables quantitatives ou qualitatives, issues d’une base de données. En sciences, elles sont souvent reliées à d’autres données. Cette relation de dépendance définit les métadonnées.
- L’information correspond aux associations et relations entre ces données. Par exemple, les données de codes Atlas sur les observations d’une espèce d’oiseau au printemps renseignent sur son statut de nicheur en France.
- Le savoir constitue la dernière étape de la démarche. A partir des informations obtenues, le Data Scientist peut identifier des patterns connus ou des tendances nouvelles. Il peut ensuite guider vers la prise de décision scientifique ou de direction d’entreprise.
Les bases de données : la montagne à miner

Les bases de données constituent donc la ressource principale à explorer. A l’image d’une région riche en gisements aurifères, il est important de savoir où et comment prospecter. La base de données opérationnelle contient l’intégralité des données brutes collectées. Le Data Warehousing désigne les procédés de collecte, de structuration et de gestion des données dans un entrepôt virtuel de données (Data Warehouse) en vue d’analyses précises.
L’idée du Data Warehousing est de segmenter les données brutes en regroupements utiles pour faciliter leur exploration. Par exemple, au lieu de chercher au hasard de l’or dans la vallée, le Data Scientist extrait du paysage tous les cours d’eau aurifères pour les repositionner en un seul site sur-enrichi ! Il ne restera plus qu’à prospecter tout l’or regroupé au même endroit avec le meilleur tamis possible.
En résumé, le Data Mining repose sur cinq actions majeures :
- Stocker et gérer des données brutes dans un système de base de données opérationnelle.
- Extraire, charger et organiser les données segmentées dans un entrepôt de données ou Data Warehouse.
- Fournir un accès aux utilisateurs à travers un interface opérationnel et des protocoles de transferts de données.
- Analyser les données grâce à un logiciel statistique pour en tirer des informations : Data Mining.
- Présenter les données et informations sous un format compréhensible (graphique ou un tableau). Rédiger un rapport final. En déduire une nouvelle connaissance scientifique ou une prise de décision.
Data Mining : le naturaliste doit-il sortir sa pioche ?
Le Data Mining est déjà à la portée du naturaliste : l’exemple le plus connu est le réseau VisioNature dont les données sont progressivement centralisées sur le portail Faune France. A partir de ces informations collectées, la LPO et les organismes partenaires effectuent déjà des analyses de Data Mining pour mieux comprendre les dynamiques des populations d’oiseaux, par exemple.
La compilation de bases de données pour systèmes d’informations géographiques permet également l’extraction de nouvelles informations. Ceci se rajoute à différents paramètres physico-chimiques ou observations diverses. Le champ des possibles en terme de Data Mining devient ainsi immense ! Le naturaliste, qu’il soit amateur ou professionnel, ne peut plus ignorer ces nouveaux outils. Dans la démarche actuelle de science participative, l’élaboration de nouvelles bases de données opérationnelles multiplie également les besoins futurs d’extractions affinées. Les opérations de Data Warehousing ont donc toute leur importance, ne serait-ce que pour la compilation de segments de données harmonisées regroupant des initiatives naturalistes similaires mais dispersées.
Enfin, à petite échelle, réflechir en terme de Data Mining permet de modifier son approche naturaliste. En effet, l’observateur sera plus enclin à noter différentes données associées, et enrichir ainsi le champ d’analyse des variables. Cela ne pourra qu’aboutir à de nouvelles informations terrain et une meilleure connaissance de la faune et de la flore, même à l’échelle locale.
Comment miner ses données naturalistes ?
Le Data Mining ne nécessite donc pas forcément de puissantes ressources informatiques personnelles. A vrai dire, il suffit d’un minimum de connaissances en statistiques et webmapping pour le pratiquer. Car dans une grande majorité de son temps de travail, le Data Scientist effectue des opérations mathématiques basiques. La plupart des calculs complexes sont réalisés directement par les algorithmes. Dans ces conditions, une maîtrise des interfaces serveurs et des logiciels de bureautique peut déjà suffire à explorer quelques jeux de données.
Par exemple, le recours à des logiciels statistiques pédagogiques et spécialisés dans la statistique exploratoire comme Tanagra (logiciel libre) répondra à ces besoins. Tanagra est un logiciel créé par un chercheur de l’Université Lyon-2. Il permet d’effectuer les traitements d’analyses factorielles telles que l’ACP, l’AFC, l’ACM. C’est pourquoi ce logiciel libre est particulièrement utile pour le Data Mining. De plus, il peut s’intégrer via une macro dans les tableurs des principales suites bureautiques (MS Excel ou Open Office). Enfin, il reste beaucoup plus facile d’accès pour les néophytes que le langage R.
Data Mining et gestion d’espaces naturels
L’usage des biostatistiques en écologie rejoint bien entendu le traitement des nombreuses données terrain collectées. Le gestionnaire d’espaces naturels tout comme les naturalistes amateurs d’une association de protection de la nature peuvent légitimement s’interroger sur l’influence multifactorielle de l’humain sur la biodiversité locale. Les données collectées sont alors multiples : inventaires naturalistes, qualité physico-chimique du biotope, données météorologiques, fréquentation humaine, enquêtes sociologiques, indices de dégradation…
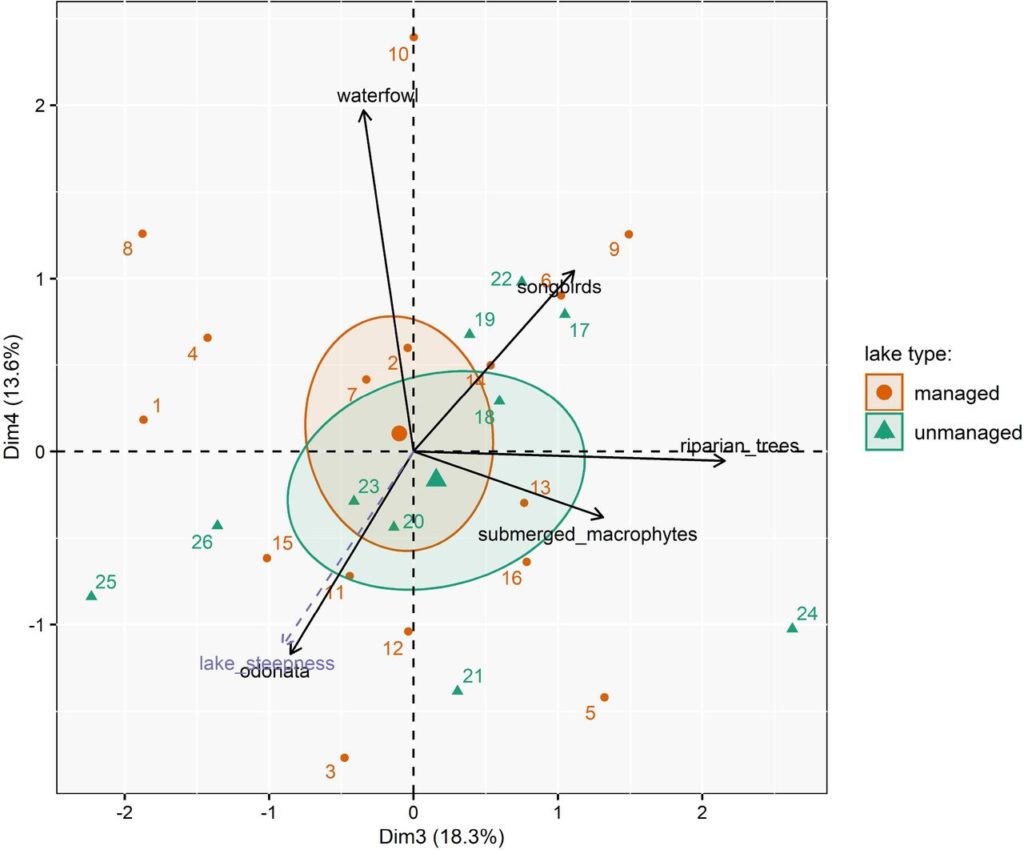
Toutes ces données nécessitent un data mining pour révéler tous leurs enseignements. Le rédacteur peut ainsi avoir recours aux outils d’analyses statistiques avancées comme l’ACP pour résoudre cette problématique. L’illustration ci-dessous en est le parfait exemple. Il s’agit d’une analyse ACP comparant des données collectées sur des plans d’eau et lacs soumis à la pêche récréative, différenciés selon la mise en place ou non de plans de gestion (Nikolaus et al., 2020) :
Une critique écologiste des Big Data
Dans une récente tribune publiée par Libération, deux scientifiques alarmaient sur « l’imposture » des Big Data pour résoudre la crise écologique actuelle. Selon eux, l’engouement actuelle pour les données est illusoire lorsque la situation appelle à une transformation profonde de nos modes de vie. Il est bien évidemment illusoire de croire que les Big Data puissent miraculeusement sortir des métadonnées mondiales la solution à la sortie de crise écologique. Tout au plus l’information obtenue permettra de guider vers une prise de décision affinée.
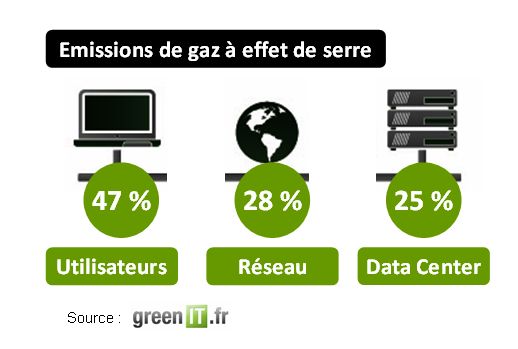
Comme tout outil, le Data Mining a ses points forts, et ses faiblesses. Mal optimisé, utilisé sans discernement, il peut devenir une terrible « usine à gaz » à centres de données énergivores. L’impact du web sur la planète est ainsi estimé à 200 kg de gaz à effet de serre et 3 000 litres d’eau par internaute et par an. De même peut-on pointer du doigt les risques de dérives politiques de l’emploi massif des Big Data dans le cadre d’études « sociétales » des populations. Mais l’idée même que les Big Data ne soient qu’un « mythe » pour soutenir la transition écologique est une idée certainement bien trop radicale.
Cependant, en l’état des connaissances scientifiques, plus personne ne peut nier l’importance des outils d’analyse à haute capacité pour la modélisation des écosystèmes. Or, pour mieux comprendre les complexes équilibres au sein de ces unités fondamentales du paysage et ainsi mesurer les conséquences des dérèglements environnementaux actuels, nous aurons besoins d’outils puissants tels que le Data Mining.