





Bienvenue sur Louernos Nature !
Logiciel R : un outil de Data Science pour les naturalistes
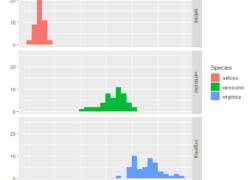
Introduction au logiciel R pour l’écologie et le naturalisme. Cet article présente les outils graphiques et statistiques pour traiter des données terrain.
L’Analyse en Composantes Principales
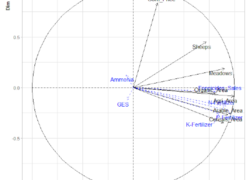
L’analyse en composantes principales est un outil incontournable en data sciences. Découvrez son application sous R avec des données environnementales.
La chasse régule-t-elle vraiment des espèces nuisibles ?

Les tableaux de chasse concernent-ils seulement 5% des espèces à réguler ? Face à la polémique des réseaux sociaux, nous analysons les chiffres de l’ONCFS.
Destruction du Choucas des tours : une mesure inutile ?

La destruction du Choucas des tours répond à une situation de crise agricole. Mais la mesure préfectorale est-elle vraiment efficace ?
Les Bases en Biostatistiques – Chapitre VIII

Présentation générale des tests statistiques et hypothèses en biostatistiques. Exemples pris des tests de Student et du khi-deux.
Agriculture : 3600 scientifiques dénoncent la PAC européenne

Dans une tribune publiée par la revue British Ecological Society, 3600 scientifiques dénoncent la « désastreuse » politique environnementale menée par la PAC.
Les Bases en Biostatistiques – Chapitre VII

La régression linéaire est un outil statistique très prisé en sciences expérimentales. Cet article initie le lecteur à sa compréhension.
Paléoclimat : décalage entre températures et teneurs en CO2

Le décalage entre température et CO2 est un phénomène paléoclimatique bien connu. Sa compréhension permet de mieux éclairer le changement climatique actuel.
Que signifie "Louernos" ?

Louernos signifie "renard" en gaulois. Un clin d'oeil aux Arvernes qui firent de la région Auvergne leur royaume à l'époque des Gaules ! Un célèbre roi arverne, Luernios, tirait d'ailleurs son nom de cet animal. Le renard souffre hélas d'une symbolique peu flatteuse dans l'imaginaire européen, qui lui vaut encore aujourd'hui mauvaise réputation.
En adoptant le renard comme logo de ma micro-entreprise, j'ai souhaité rappeler au combien la nature est encore victime de préjugés, mais que grâce à l'éducation et la connaissance, nous pouvons œuvrer concrètement en faveur de sa protection.