
La régression linéaire vous est peut-être aussi familière que la prose pour Monsieur Jourdain. Et peut-être au cours de ce nouvel épisode vous exclamerez-vous : « Par ma foi ! il y a plus de quarante ans que je dis de la régression linéaire sans que j’en susse rien, et je vous suis le plus obligé du monde de m’avoir appris cela. »
Car durant ces épisodes précédents, une remarque est venue se mêler à nos considérations statistiques. Mais reprenons notre raisonnement où nous l’avions laissé au chapitre premier. Soit deux variables aléatoires X et Y. Le signe de leur covariance Cov(X,Y) et la valeur du coefficient de régression r nous indiquent alors s’il existe une corrélation entre-elles.
Mais comment procéder si nous voulons plus de renseignements sur cette corrélation ? Si nous considérons la variable aléatoire X comme premier caractère, pouvons-nous lui attribuer une qualité prédictive ou explicative concernant les valeurs possibles de la variable aléatoire Y ?
Pour répondre à cette question, les mathématiciens proposent deux approches possibles, mais au final assez complémentaires. Premièrement, la solution au problème est probabiliste. Il faut définir une espérance conditionnelle qui explorera les valeurs possibles de Y en fonction de X. Deuxièmement, la solution est géométrique. Il faut tout simplement tracer un graphique des valeurs de (X;Y) et étudier le nuage de points obtenus. Si une allure linéaire apparaît, alors nous tenons là notre réponse.

7. La régression linéaire
7.1. Droite de régression
Pour commencer, utilisons le modèle le plus simple pour exprimer la relation entre X et Y. En effet, la relation entre les deux caractères est représentée graphiquement par une droite de régression y = a.x + b .
Aussi, la droite passant le « plus au milieu » du nuage de points correspond à la droite pour laquelle la somme des carrés des écarts verticaux de ses points est minimale. C’est à dire que notre modèle va prendre en compte la dispersion du nuage de points pour calculer les coefficients estimés a et b de l’équation de la droite de régression. En mathématiques, cette méthode se nomme la droite des moindres carrés.
Pour cette méthode, nous obtenons les coefficients suivants :




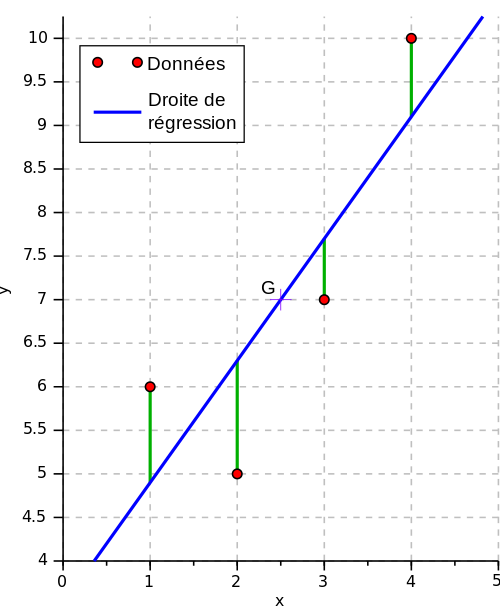
Dans ces formules, les valeurs x̄ et ȳ correspondent aux coordonnées du centre de gravité du nuage de points G(x̄ ; ȳ). Pour dessiner ce point sur votre graphique, il suffit de calculer les moyennes respectives des valeurs de X et de Y. La droite de régression passe alors par ce point moyen. En voici une illustration ci-dessous :
7.2. Variance expliquée et variance résiduelle
Comme nous l’avons vu précédemment, la méthode des moindres carrés permet d’obtenir la droite qui minimise la somme des carrés des écarts entre les valeurs Y prédites et les valeurs Y observées. Cela revient à considérer que la régression peut s’écrire Y = a.x + b + Ɛ , où Ɛ est la variable aléatoire de l’écart vertical pour chaque point avec la valeur prédite (lignes vertes sur le graphique précédent).
Tout d’abord, nous pouvons démontrer que les variables aléatoires a.x + b et Ɛ sont indépendantes. Nous obtenons ensuite deux formules de variances, la variance expliquée Var(a.x+b) et la variance résiduelle Var(Ɛ). Enfin, ces variances peuvent ensuite être prises en compte dans des tests d’hypothèse du coefficient de corrélation. Mais ceci est une autre histoire !
7.3. Qualité de la régression
Enfin, la régression linéaire permet d’attribuer un indicateur de qualité appelé coefficient de détermination R² . Cet indicateur est bien connu des utilisateurs de MS Excel, puisqu’il peut être obtenu en même temps que le tracé et l’équation de la droite de régression.
Pour l’obtenir, il faut donc procéder à une comparaison des écarts entre le nuage de points et le modèle prédictif obtenu. A partir du tracé de la droite de régression (yi), du centre de gravité (ȳ) et du nuage de points (ŷi), nous calculons le tableau d’analyse de variance suivant :
| Source de variation | Définition | Formule |
|---|---|---|
| SCE | Somme des Carrés Expliqués | SCE = ∑(ŷi-ȳ)² |
| SCR | Somme des Carrés Résiduels | SCR = ∑(yi-ŷi)² |
| SCT | Somme des Carrés Totaux | SCT = SCE + SCR |
Le calcul de SCE et SCR évoque d’ailleurs en partie le calcul d’une variance, car nous avons bien la somme des écarts à une valeur de référence mise au carré.

La valeur de R² est ensuite prise en compte dans notre réflexion. R² = [0;1] .
- Si R² = 0 alors le modèle n’explique rien, les variables X et Y ne sont pas corrélées linéairement.
- Si R² = 1 alors les points sont alignés sur la droite, la relation linéaire explique toute la variation.
- Entre ces deux valeurs, à vous de juger si la relation linéaire est valide ou non !
En conclusion, ce coefficient de détermination permet aussi de juger de la corrélation entre nos deux variables aléatoires X et Y. Cependant attention à ! Corrélation n’est pas causalité, et les statistiques s’arrêtent là où la raison prend le pas. Il vous faudra donc vous plonger dans la bibliographie scientifique pour conclure à la pertinence biologique de votre régression linéaire…
Quelle est la suite ? Dans l’épisode VIII, nous rejoindrons les derniers Jedis avec les tests d’hypothèse. Ce chapitre introductif nous présentera la méthodologie générale, ainsi que deux tests désormais classique : le test de Student et le test du khi-deux.